
A common question I see out there is if the RPC Client Access Service (including Client Access Service Arrays) can access databases in other sites. The answer is, yes. Let’s take a look at a couple scenarios.
Scenario #1 – Full Site Failure
Let’s say you have a Client Access Server Array called array.domain.com. Primary Site goes down. As a part of the manual site switchover process, you must update the DNS records in your Primary Site to point to the CAS infrastructure at your DR Site. One out of several DNS records you change will include the CAS Array. You change array.domain.com to point to DRSiteCAS instead of PrimarySiteCAS. The client (after the DNS record flushes – recommended for TTL value to be 5 minutes for DNS records in site resilient solutions) will then start to connect to the DRSiteCAS which will then access the database in the DR Site.
Scenario #2 – Server Failure(s) in Primary Site and Disabling Automatic Activation for Databases and Servers
In the case where all database copies go down in the Primary Site, your databases can automatically failover to the DR Site as long as you allow automatic activation on the DR Servers (yes, you can turn off automatic activation on databases and servers) and as long as you still have Majority for your Quorum. In this scenario, the RPC Client Access (and array) can access the mailbox databases that are mounted in the DR Site.
Automatic Activation
As I just eluded to above, it is possible to turn off automatic activation on databases and servers. There is something called Database Activation Policy. Let’s say you wanted to disable a specific database from being considered in the Automatic Activation Process.
You can use the following command to prevent the database from being considered in the Automatic Activation Process:
This example resumes the copy of the database DB1 on the server MBX2 for automatic activation:
This is also possible to do at the mailbox server level using the Set-MailboxServer cmdlet. You can use the following command to prevent any databases on a specific mailbox server from being considered in the Automatic Activation Process:
This example resumes all database copies on the mailbox server “MailboxServer” for automatic activation:
Example
Let’s say we have 6 DAG Servers with 4 in the Primary Site and 2 in the DR Site with no modifications to the Automatic Activation Policy (DAG Servers in the DR Site can automatically mount databases). Let’s say, we currently have a lack of funds for storage which prohibit the ability to have mailbox database copies on all servers. So PrimarySiteMBX01 and PrimarySiteMBX02 in the Primary Site are mirrored in terms of mailbox database copies. PrimarySiteMBX03 and PrimarySiteMBX04 in the Primary Site are mirrored in terms of database copies. PrimarySiteMBX01 and PrimarySiteMBX02 are mirrored with SecondarySitMBX0102 in the DR Site and PrimarySiteMBX03 and PrimarySiteMBX04 are mirrored with SecondarySiteMBX0304 in the DR Site.
To make it a bit more clear, the following image shows database distribution. You can see there are 6 nodes and 3 copies of each database.
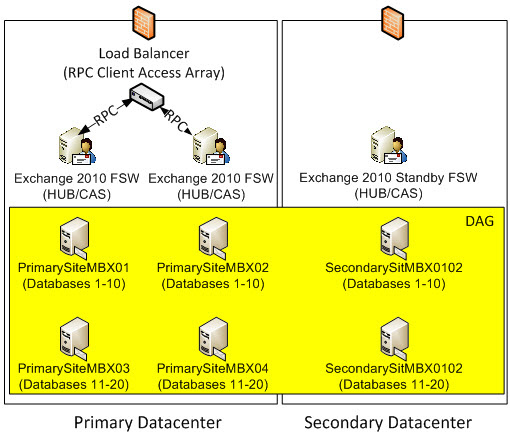
Should PrimarySiteMBX01 and PrimarySiteMBX02 go down (as illustrated below), SecondarySiteMBX0102 can automatically mount the database because majority is still there for quorum. In this case, the RPC Client Access Array in the Primary Site will still successfully be able to provide mailbox access to the databases mounted on SecondarySiteMBX0102 in the DR Site. This is one of the nice things I like about Exchange 2010 High Availability, is that if your DAGs go down, you can allow the copy in the DR Site to automatically activate (provided the Database Activation Policy as described above allows it to automatically mount) whereas in Exchange 2007, you had to manually activate any SCR copy.
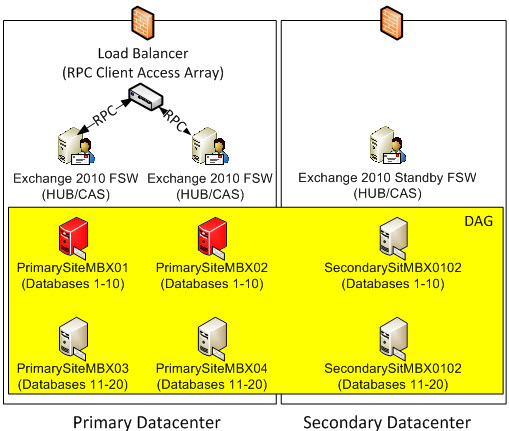
Exchange 2007 and Exchange 2010 Clusters both use Majority Node Set Clustering. This means that 50% of your votes (server votes and/or 1 file share witness) need to be up and running. With DAGs, if you have an odd number of DAG nodes in the same DAG (Cluster), you have an odd number of votes so you don’t have a witness. If you have an even number of DAGs nodes, you will have a file share witness in case half of your nodes go down, you have a witness who will act as that extra +1 number.
So in this scenario, we have 6 votes from the servers plus 1 witness from the file share witness totaling 7 votes. This means we can have up to 3 servers fail and our cluster will still be online. This is because if you are in the scenario where we 7 votes, if 3 go down that leaves us with 4 votes which satisfies the 50% + 1 majority rule. Because of this, we still have majority and our quorum and cluster are still fully operational.
Now when exactly would we have to do a manual switchover? Well, there’s a couple cases. The first would be if your Primary Datacenter has a complete outage. This may be due to power failure, environmental disaster, etc… The other is because all Primary Datacenter DAG members go down or just enough servers go down (again, 50% + 1 voters must be up which means if we lose more than 3 machines (includes FSW), our entire cluster goes offline. In this case, you’ll have to do a manual datacenter switchover. You’ll move over all services to the secondary datacenter including changing the RPC Client Access Server FQDN to point to the single CAS Server or the standby VIP that publishes RPC across multiple Secondary Datacenter CAS Servers.

Hi there! This post couldn’t be written much better! Looking through this post reminds me of my previous roommate! He continually kept preaching about this. I will send this information to him. Fairly certain he’ll
have a very good read. I appreciate you for sharing!
This is very interesting, You’re an excessively professional blogger. I have joined your feed and stay up for searching for more of your wonderful post. Additionally, I’ve shared your web site in my social
networks
Do you have a spam problem on this site; I also am a blogger, and I was wanting
to know your situation; many of us have developed some nice procedures and we are looking to trade methods with other folks, why not shoot me an e-mail if interested.
Hello there, You’ve done a great job. I’ll certainly
digg it and personally suggest to my friends. I’m confident they’ll be benefited from this website.
I must thank you for the efforts you’ve put in penning this website. I really hope to view the same high-grade content from you in the future as well. In fact, your creative writing abilities has inspired me to get my own website now ;)
i have two AD sites. One is Gurgaon & second is Chennai. it is a scenario of DC & DR Sites. Gurgaon is DC site & chennai is DR site. i have two mailbox servers in DC site & two mailbox servers in DR sites. i have 3 database on gurgaon mbx server & created database copy on chennai servers. i have enabled databaseautoactivation policy means i blocked database to auto mount in DR site.
Now i created one cas array outlook.domain.com & set to all three databases created in Gurgaon mbx servers. i have not created any cas array on DR site.
My question is: when my DC site goes down, how client will connect to DR site cas server. should i create one more array in DR site. is it possible to create one more cas array. i think yes because it is second site but databases in DR site is a copy of DC site mailboxes so can i connect second cas array on same databases in DR site.
or when my Dc site goes down i need to change DNS cas array record point to DR site & after that create NLB in DR & than create cas array & set to database.
Please reply..
Hello Elan,
Our current E2K10 DAG environment is exactly the same as your Example mentioned above. Our secondary datacenter is holding the passive copies only. These two datacenters are in different AD sites. All the mailbox servers in the primary datacenter is serving all the Outlook, OWA, and EAS connections.
Last week we tested manual switchover (from primary to secondary) with the WAN link severed and it went well.
However, I have one question about the CAS Array. In the primary datacenter, we have HW load balancer to handle the requests from Outlook and OWA/EAS. In the secondary datacenter, there is only one CAS server.
With the WAN link up, the users in the primary site can still access their mailboxes even we move the databases from the primary datacenter to the secondary datacenter. However, the users cannot access their mailboxes in the primary datacenter if they try to request through the CAS server in the secondary catacenter. In this case, do I need to create an additional CAS array for the secondary site or it is just a normal behavior?
Thanks,
Kevin Yeung
Kevin,
You should not have to create an additional CAS Array. The CAS Array FQDN would just be updated to point to the CAS Server in the secondary site (which sounds like you did this) and it should just work. If it doesn't work, you'll have to start troubleshooting RPC CAS issues on that CAS Server. But again, it should work as I have tested this many times without issue.
Elan
Elan,
Thank you for getting back to me. Yes, I agreed with you. In our first DR test, I did not have any CAS array created in the DR site. After I moved all the databases to the DR servers and severed the WAN link, I updated the DNS there and everything worked.
I have one more question; if all the mailbox databases are hosted in the primary datacenter, the users should not be able to use the CAS server in the DR site to access their Outlook and OWA (internal and external). Is it correct? Is it because all the mailbox databases are registered to the CAS array in the primary datacenter?
Thank you for your help.
Kevin
Well the RPC Client Access Service does have the capability to access Mailbox Server's RPC Client Access Service in different sites. So it can work. In your scenario, since it's a DR Site and you transitioned the FQDNs over to the DR Site, your DR site CAS Servers won't be able to properly redirect back to the Primary Site since the DNS has been transitioned. So yes, you want your databases to remain in the DR Site and then schedule maintenance and transition everything back.
Hi Elan,
I have an existing client access array for exchange 2007. I have now installed 2 exchange 2010 CAS servers (Same AD site.Same forest, same subnet where the exchange 2007 cas/ht/mbx servers reside). When I run the get-clientaccessarray cmdlet on Exchange 2010, I get a blank response. I checked and the CAS array with the FQDN of prod-mailbox.xyz.com does exist for this AD site. So here's my question, when the clients mailboxes are moved to the new exchange 2010 database, the outlook user profile will still point to the existing cas array (prod-mailbox.xyz.com) yet, the mailbox will not be there.
The existing exchange 2010 mailbox servers and databases are pointing the localhostname.server.name for CAS. How can I create or add these servers to the existing CAS array or can't I?
What will happen? I hope I didn't' ramble on too much, but this is a huge concern.
Thanks in advance for your response.
Tash
You said you don't see anything with get-clientaccessarray. Yet you say you checked and the CAS Array with the FQDN does exist for the AD Site. What you're not telling me is how you saw that so not sure how I can help you since you just contradicted yourself.
Hi,
I'm planning an Exchange 2010 site resilient for my company with the Active/pasive architecture using diferents namespaces.
I have 2 sites with one server on each with the 3 roles (cas,hub and mailbox). My idea is to implement 1 DAG in order to have 1 active database in primary site and the replicated in the passive site.
Also have 1 witness server on active site for the quorum requirement
Do I need to have Exchange server roles separately on diferents servers or its works having all the roles in the same machine? I don't have load balancer, only 1 CAS, hub and mailbox.
Summarizing:
Active Site
1 server with roles mailbox, hub and CAS
1 witness
Passive site
1 server with roles mailbox, hub and CAS
Both sites with differents namespaces.
Thanks!
Mauricio
Looks good. You can use multi-role servers. Just make sure you spec the servers out with enough resources. Here's a start: http://technet.microsoft.com/en-us/library/dd2981…
Hi,
We have 2 Datacenters/AD sites (primary and DR), 1 DAG with 2 members, 1 DAG member in each AD Site. Active DB and all users in primary site passive copy in the DR site. We also have 2 CAS Arrays, 1 in each site. FWS in primary site and alt-FWS in DR site. DAC enabled.
The problem is that when the FWS in the primary site is down (e.g. restarted for updates etc) then the active databases automatically failover to the DR site. Is there any way to stop this happening? Ideally failover should only occur if the primary DB is down or the primary site fails not if the FWS fails.
thx
Mark
That's definitely not normal. Not sure what would be causing this. Sorry.
Yes you can configure the autoactivation policy to be blocked on the DR site, in the event that you want it activated you reset it to unrestricted.
Set-MailboxServer –identity DRdag –DatabaseCopyAutoActivationPolicy Blocked
I agree design wise a site fail over should be manual.
Hi Elan,
Please Help
300 users divided equally between 2 sites, A & B. Single Ad domain but 2 corresponding AS sites. Each site with 1 CAS/HT server and 1 MBX . Mailbox server resilience to be provided y DAG. I.e Site A will have a DAG on the Site B MBX server.
The challenge i have is following; I want to provide resilience for CAS. Ideally , A CAS Array would be great if not for the fact that my 2 CAS servers live in different AD sites. What I would like to happen is following;
1. IN normal use when both CAS servers are operating ok, I want users to be able to use the CAS server that is relative local to them. If site A is in Europe and Site B is in the US, I want european based users to use the europe CAS server in site A.
2. If the CAS server in Site A (europe) goes down , I want the user to then be directed to the CAS server in Site B ( in the USA) and from their get connected back to the mailbox server at site A or if that server is down as well, to be connected to the DAG in site B
Hi,
We have 2 Datacenters/AD sites, 1 DAG with 2 members, 1 DAG member in each AD Site that has the Databases for users in that site active, and the passive copy on the opposite datacenter. We also have 2 CAS Arrays, 1 in each site.
Because of cost restrictions, I cannot have 2 DAG members with copies of the databases on the same Datacenter. Each data center will be backup of the other. The Mailbox stores will have the local site RPCClientAccessServer property…
Now my question is on Majority set. Since I will only have 1 DAG on each DataCenter, I was wondering how I can prevent split brain syndrome and keep both DAG members alive ( Cluster online ) during a network failure.
Thanks !!!
Completely second DAG or put FSW in 3rd site. Problem with FSW in 3rd site is if your primary site is very important and the WAN link goes down preventing access to the secondary datacenter and the site that has the FSW, that primary datacenter goes offline.
HI Elan,
I have one question…
We are in process of creating DR Site for Exchange 2010. Current set up is we have a 2 Exchange server Hub/cas/mailbox server in Head office with DAG.& we have mail marsahl server which is act as aSMTP Server.
In DR SITE , We are planing to install 1 DC &one Exchnage 2010 Hub/cas/Mailbox server in same Head offfice DAG.
My Requirement is that
1. If head office internet Leased line is down,the mail should forward to DR SITE. (I will install new internet Leased Line & create new mx record for his site with Hogh Priority.so if head office line down, the mail get forward to DR Site. is this correct?)
2.If head office site entirly down, Users should access mail from DR Site.(Does switchover process will be automatic from DAG Site. 2.Wwhat about outllok configation from Client side & what about owa.Do i need to change anything from Client side or server side)
regards.
1. Yep, this is done with MX records.
2. Both. There's a lot of considerations. This is a good start: http://technet.microsoft.com/en-us/library/dd3510…
Hi Elan, Great articles…
I want to know the steps of configuring CAS site failover? We have two sites with two diff. AD, like Site A & Site B. We have configured CAS,MB & HB on our two servers on both the sites. Now we want to test CAS Failover on sites. Please suggest us.
Regards,
Sam.
This is all outlined in the following site: http://technet.microsoft.com/en-us/library/dd3510…
There are a lot of steps and "if then this" so the steps may differ depending on how things are set up.
Hi Elan,
We have 3 locations office London ( Primary site), datacenter London ( CAS), datacenter Belgium ( backup site). The idea is to have a 2 server DAG office London & Belgium, CAS/HT/FSW wil run on a cluster in the London datacenter. If the primary site fails all our external users can continue to work. The internal users in the London office will loose their connectivity. Placing a 2nd CAS at the London office and point clients within the London office to their local CAS would solve this problem right ? Any better suggestions to deal with this ?
FSW should not be on the DAG Members. I believe you meant MBX, not FSW. Huge difference. :)
If the entire Primary Site where the DAG lives fails, all users no matter where they are go offline. I have many articles that go into this in detail. Google me with the words Majority Node Set to understand why. You would need 2 DAGs to take care of users going offline if WAN fails or if entire Primary Site goes offline.
Hi,
Do wee need to set the TTL for DAG Name to 5mins for Multisite DAG.
Since the DAG is fully managed by Exchange in DAC mode, is there any powershell command to do that ?
Hi Elan:
We have one site with three DAG members. We are creating an additional failover site with one DAG which will hold just the passive copied and HT/CAS server. I have quick questions about namespace:
1) Use same namespace mail.company.com and in case of site failure, we can just change DNS to point to failover CAS server.
2) Use separate namespace failover.company.com.
In your experience, what is best advise and recommended?
Well, you need to have a different namespace as you can't use the same namespace in both sites. When it fails over, you can switch over your primary datacenter's namespace by changing DNS. This means that the secondary datacenter's certificates need to include FQDNs for both the primary site as well as the secondary site. You'll want to configure the InternalURLs for the secondary site to use the secondary namespace. Users will never really use that in your case though since they'll always be configured to use the primary site's namespace since that's where their configured client access array belongs. If you recall, you configure what site the rpc client access array belongs in. Because you're configured to use that array, you always get the FQDNs defined in the primary site, even during a failover.
Hi Elan,
nice article. thanks.
just have a couple of questions to make sure:
1. I assume from your diagram Primary site and Secondary site are on same AD site, thus the same AD site are stretched across 2 data centers?
2. am I correct to say the principals (as in quorum decision, database activation, etc) are the same regardless of either the DAG members are on same/different AD site?
thanks,
My article isn't based off of stretched AD Site but it wouldn't matter (which answers your 2nd question). All that matters (we're not talking about activating a second site here) is that you need to have (number of nodes / 2) + 1 servers (the +1 will be the witness if running an even number of nodes) online in order to stay operational.
Hi Elan, thanks for your help so far. Just to recap / summarise….
1. 2 x CAS Arrays (one for each Data Center with its own seperate HLB setup).
2. Outlook 2007+ Users will locate the correct CAS Array using AutoDiscover.
3. OWA Users will use single name space e.g. webmail.domain.com (I don't want to give out 2 separte URL depending on which Data Center their mailbox is hosted on). So I setup HLB for webmail.domain.com (redirecting to CAS Array 1 and 2). Which means that a users have a 50% chance of accessing the correct CAS and if not the ExternalURL will redirect them to the other Data Center – is this the best way to load balance the OWA?
Hi Elan, regarding OWA – about 60% of the users will be using OWA (all internal users). Using your sugguestion of a single namespace e.g. webmail.domain.com would it be advisable to also HLB on top of the other the 2 HLB CAS Arrays? From what you saying above if wrong CAS is accesed by the user then the CAS will proxy to the correct CAS?
You can just use the same HLB for OWA that you're using for one of your CAS Arrays. And if you decide to do CAS redirection instead, one namespace can using the HLB for one RPC Array and the other namespace can use the HLB used for the other array.
Thanks Elan for your quick response which now leads me to some questions on the client side…
1. From the various remote sites that the users physically reside – how will their outlook client know which CAS Array to use? or will Auto discover work it out?
2. To load balance both arrays I presume I will need Hardware Load Balancer for each array?
3. How will OWA users be handled? will I need to have 2 URL's depending which Data Center they are hosted on?
1. Autodiscover for Outlook 2007+. Manually for Outlook 2003.
2. Correct. Need separate HLB setups in each Datacenter.
3. OWA has no real bearing. You can have one namespace such as webmail.domain.com and have that proxy to the second site or re-direct if there's ExternalURLs set in the secondary site. On the backend, OWA will do lookups to see what database you're on and then contact that RPC CAS to get access to database information.
Hi Elan,
Great post, I have a query which I hope you can advise me on.
We have 2 Data Center with 50% of users in each. How can I ensure users connect to the correct CAS on the Data Center that the users mailbox resides? What I don't want is user to connect to a CAS on Site A but their Mailbox is on Site B.
Would I have 1 Cas Array spanning both Sites or 2 Cas Arrays?
Thanks
So, in your case, you can have 2 CAS Arrays. One for each site. Then for the databases that will be mounted in that site, you stamp them with the RPC Client Access Array in their given site. For example, let's say we have Site A and we create a CAS Array called casarrayA.domain.com. We then take all databases that will typically live in that site and do a Set-Mailboxdatabase SiteADatabase -RPCClientAccessServer casarrayA.domain.com.
wonderful post.
I have a scenario now and i sincerely hope you can help me.
A forest with multiple domains and i have an exchange server 2010 in Singapore with 2 hub/cas in a NLB and 2 mailbox servers. And these Exchange servers serves the Asia Pacific region users from different AD site. i have created a new array:
new-ClientAccessArray -name SingaporeCAS -fqdn cas.singapore.domain.com -Site Singapore
However, I have Malaysia AD site (and others), what do i need to do so that they can those users can point to the server for autodiscover and automatically map those users at Malaysia to the CAS array server?
Thank you.
So the way the user's connect to their RPC Client Access Array is what is stamped on their database. You can see what I mean here: https://www.shudnow.io/2010/04/18/creating-databa…
So if you have a single DAG and you want to host active databases in both, just create two RPC Client Access Arrays and for the databases that will live in a specific site, just stamp those specific databases with the correct RPCClientAccessServer Parameter.
You can also look into something called Autodiscover Site Affinity if you want to scope requests for a specific location to specific CAS Servers. I also blogged about that topic here: https://www.shudnow.io/2008/08/24/configuring-exc…
Hi Elan,
Thanks for a great post – but I do have one question.
You've started talking about what happens if my entire primary datacenter fails – the question is what happens to the SecondarySiteMBX0102 (in this case)?
I mean, it loses conenction the the FWS and to the other active roles – wouldnt he auto mount the DB's?
and lets make it even more complicated – lets say that the primary datacenter is still active, but connection between the two sites is down – would i have a brain split?
The Secondary Site will lose Quorum. Remember, in a Majority Node Set Cluster Mode, in order for the cluster service to be operational, you need to have (n / 2) + 1 nodes to be operational which includes the FSW. n stands for number of Mailbox Server Nodes. You'll always have the FSW and the majority of the nodes in the primary. Because of this, if the Primary Site goes offline, the entire cluster goes offline which includes the secondary site. This will require manual failover to the secondary site. The same happens for WAN outage. The secondary site doesn't have majority so its cluster services begin to fail.
Got it, I also just read your post about DAC which also helps to figure it out.
Thanks!
in each AD site where you have a mailbox role, you need to have a CAS server/array. So if none of the CAS servers are available in an AD site, Outlook client will fail to connect.
Therefore, as you've mentioned, the DAG will need to be failed over and the Site A CAS array DNS record pointed to the CAS array in Site B. Since the outlook profile is configured to connect to Sie A CAS array, once the DNS cache is flushed (say after 5 minutes), Outlook should start connecting via CAS in Site B using the same namespace.
in a site level failover, changing only the DNS record will work? still the rpcclient access server attribute at databases are still pointing to old CAS Server?
pls reply
That is correct. You only need to change DNS. The RPCClientAccessServer attribute stays the same. You change DNS so now it technically points to the new server in the 2nd site.
Hi Elan,
I have done various testing on this scenario and the outcome is that the RPCClientAccessServer attribute must be pointed to the second array in the secondary primary datacentre in the event of a full site failover, this is an additional step to the DNS change.
Cheers,
Khanh
I've done production DR Failover tests where I have not had to update the property. Just change the DNS. In fact, three things.
1. The official documentation for datacenter switchovers do not have you update the RPCClientAccessServer Property
2. I have discussed this with the Product Group during the development of Exchange 2010 and their official guidance to me was specifically called out to not update the property and just update DNS instead
3. There's actually an issue with the RPC Client Access Server and Autodiscover in which changing the RPC Client Access Server property won't automatically update a client to use the new RPC Client Access Server if you do not do a manual repair on Outlook.
Hi Elan,
I have a question regarding CAS Array failure. If a CAS in site A or, if you're very unlucky, all servers in your CAS array fail at the same time in site A but your active mailboxes are still on servers located in site A. What will happen to the outlook clients? They are configured for cached mode so they'll have access to historical data but will lose their RPC connection but Public folders should still be ok?
My question is, in order to utilise the CAS or CAS Array in site B, will you have to fail over the active databases to site B and reconfigure the RPC Client Access endpoint to be the active databases in site B? Using Autodiscover the clients will then reconnect to the CAS / CAS Array in site B?
Alternate solution is to configure Outlook to connect using HTTP on slow connections and update external DNS to point to CAS/CAS array in site B? The second option obviously ensures access for remote users too but wondering about option 1 as well.
Many Thanks
Una
Hi Elan;Thanks for great article.
I just have a question about cas server in multiple active directory scenario.
I have two sites exchange 2010.Both of them has cas and mailbox server.But only sitea cas server is internet facing.So i enabled outlook anywhere on sitea cas server.If a site a user tries to connect from external, outlook anywhere working fine.
On the other hand because of siteb cas server is intranet facing, i set the authentication method integrated authentication instead of fba.So When a siteB user make a owa attempt, siteA cas server prxying this attemp to the intranet cas server.
By the way i installed a certificate from local ca to the siteA Cas Server.And no certificate for siteB cas server.Just default ceritificate.
But i need to know that, what happens when siteB user tries to connect outlook anywhere.He will find the siteA cas server.But this SiteA cas server will not proxy this connection attempt for rpc.
Is this SiteA internet-facing cas server will communicate directly siteb mailbox server for siteb user?
Or when a customer has 2 active directory sites and only one internet facing cas server, how will i configure outllok anywhere for both sites?
Hello again elan.
It works great thanks alot.I have another interesting question.
—–
i have two sites.
Each site has exc 2010 mailbox and cas server.Only one cas server is internet -facing.
When a site1 user(mailbox is resides on site1) goes to site2 location and logon to this domain, his outlook connection status showing site1 cas server for directory and mail.
is this normal? i would now that when a user goes toı another site that has cas server, all outlook connections goes over this site’s local cas server.
But in my environment according to outlook connections status, each client connecting their mailboxes which resides on different site, over remote their cas server.—
Thanks for info.I have only one internet facing cas and one intranet facing cas on another site.
I didn't configure autodiscover on external dns.But clients rpc over https configuration tabs are configured to use my internet facing cas.
You mean that , with this kind of configuration there is no additional step , users from siteb will use sitea cas server as outlook anywhere, and this sitea cas server will directly comminicate siteb mailbox server?
Well, do ı have to configure intranet cas server to use my certificate or it doesn't matter? Only internet facing cas must be configured with this certificate?
Well, again, look at that article. It talks about EVERY service in an internet facing and non-internet facing situation. The Outlook Anywhere will do a direct connection but all the other services do CAS to CAS proxying which means that certificates are indeed important. Clients connect via Autodiscover to the Internet Facing Sites, get the ExternalURL property of your Internet Facing CAS Servers, then HTTP Services (other than Outlook Anywhere) will proxy to the non-internet facing CAS via the InternalURL. This means that the certificate in the non-internet facing CAS Site must contain the InternalURL FQDN.
thanks.i'll give it a try tomorrow.
Hi Elan;Thanks for great article.
I just have a question about cas server in multiple active directory scenario.
I have two sites exchange 2010.Both of them has cas and mailbox server.But only sitea cas server is internet facing.So i enabled outlook anywhere on sitea cas server.If a site a user tries to connect from external, outlook anywhere working fine.
On the other hand because of siteb cas server is intranet facing, i set the authentication method integrated authentication instead of fba.So When a siteB user make a owa attempt, siteA cas server prxying this attemp to the intranet cas server.
By the way i installed a certificate from local ca to the siteA Cas Server.And no certificate for siteB cas server.Just default ceritificate.
But i need to know that, what happens when siteB user tries to connect outlook anywhere.He will find the siteA cas server.But this SiteA cas server will not proxy this connection attempt for rpc.
Is this SiteA internet-facing cas server will communicate directly siteb mailbox server for siteb user?
Or when a customer has 2 active directory sites and only one internet facing cas server, how will i configure outllok anywhere for both sites?
The Internet Facing CAS SErver for Outlook Anywhere will make a direct Mailbox Server connection. Look at the following article at the Summary of Client Access Methods at the bottom:http://technet.microsoft.com/en-us/library/bb3107…
You will see that Outlook Anywhere doesn't do any proxying but it does make a direct Mailbox Server connection via RPC.
Autodiscover is smart enough to assign the FQDN of the Internet Facing CAS Server even if they are in an intranet facing site as the Outlook Anywhere Endpoint for a user's Outlook 2007/2010 profile. In fact, if you had 5 internet facing sites and 5 intranet facing sites around the world, Autodiscover is even smart enough to look at your AD Sites and look at your Site Link architecture to determine whcih is the closest Internet Facing Site to assign to the non-internet facing user's Outlook profile.